
Description
This is an outline of the capabilities of the data and analytics team, how the team will engage and support key stakeholders and groups in the organization, and how to best make requests and/or communicate with the team. It is understood that the model will change over time as company priorities change and the team itself grows.
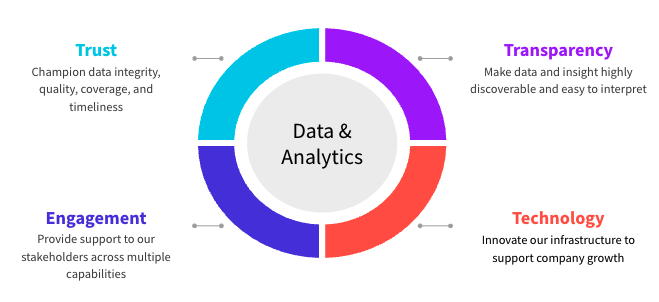
Our Vision and Values
Partner with the organization to build scalable data solutions and insights to help the company grow
Our Current Capabilities
| Data Analytics | Data Engineering |
| Analysis/Proactive Insights | Engineering/Architecture |
| Dashboards | Data Transformation |
| Stakeholder Management | Maintenance |
| Support | Tool Administration |
| Testing/Experimentation | Monitoring/Alerts |
Communications/Asking a Question
The Data and Analytics team will strive to be Handbook first. Have a question? Look for the answer in our Handbook page: Analytics Handbook Page. Don’t see what you are looking for? Ask a question in one of our Slack channels.
- #data-analytics-internal for internal Data & Analytics communication
- #analytics for anything related to analytics; not just the Data & Analytics team (e.g the impact on a shift from HubSpot to Marketo, sharing a deliverable that has cross-functional impact, or a question related to data you don’t know where to ask).
- #analytics-review for help with self-service and WIP data projects (questions about the data, requests for peer review). Although we do expect to be involved in this quite a bit, it’s not just meant to get feedback from Data & Analytics. We will also be using this channel to have our work peer reviewed and collaborate with other folks from different parts of the business! Anybody comfortable enough with data can be a peer reviewer or answer questions
- #data-eng for Data Engineering communication
There is an analyst on support each week that will be answering questions and triaging requests that come through these channels.
How to know what we are working on:
Data and Analytics Project Board (Here)
Stakeholder Support Model
The analysts will be aligned to the business units that are supported, and each stakeholder will know who their point of contact is. This allows the analyst to build relationships, embed in a specific group to become a subject matter expert, and advocate for prioritized engineering work as needed.
| Group | Stakeholder (VP/Dir) | Data and Analytics |
| Product/Engineering | Quinn Slack | Eric Brody-Moore |
| Customer Engineering | Aimee Menne | Kelsey Brown |
| Sales and Ops | Greg Bastis, Ajay Uppaluri | Kelsey Brown |
| Marketing | Nick Gage, Andy Schumeister | TBD |
| Customer Support | Kelsey Brown | |
| People/Recruiting | Carly Jones | Eric Brody-Moore |
| Finance | TBD |
The engineering team will be considered a shared service that will prioritize the requests across all business units and will adhere to an agreed upon ratio of prioritized tasks and self-directed tasks like addressing tech debt, optimizations, and platform health and administration.
Stakeholder Partnerships
Data and Analytics responsibilities
- Align Data and Analytics OKRs to stakeholder OKRs
- Gather project requirements and define the definitions of done for each project and task
- Assign deadlines for projects
- Communicate overall team priorities
- Adhere to agreed upon deadlines and communicate as soon as deadlines need to shift
- Gather feedback from stakeholders and teams as needed
- Enablement/documentation
Stakeholder responsibilities (VP/Dir)
- Keep us up to date on planned OKRs to ensure that our OKRs are aligned
- Prioritize large projects
- Help communicate resource constraints and priority trade offs to your teams/Be a tie-break when we cannot accommodate all requests
- Communicate shifts in priorities
- Enablement adoption
- Champion adoption and engagement of data deliverables/solutions within your teams
Project Requestor or Point of Contact responsibilities (Dir and below)
- Partner in requirements gathering sessions
- Agree on timelines and definition of done
- Respond to questions and clarification requests
- Gather timely, actionable feedback from team members and communicate them back to Data and Analytics
- Champion adoption and engagement of data deliverables/solutions within your teams
- Provide testing and usability feedback
- Enablement/documentation
Suggested Meetings
- Stakeholder/Analyst meetings
- Bi-Weekly or Monthly meetings to share updates of ongoing projects, talk through upcoming projects, priorities, and planning, and share new and notable work from other parts of the analytics organization.
- Project Requestor/Point of Contact meeting
- For the duration of a project, weekly or bi-weekly meeting to share updates, blockers, timelines, and progress
- Depending on the scale of the project, these meetings could alternatively be asynchronous status updates
- Retrospectives
- Retrospectives will be held at the conclusion of any cross-functional, multi-month project
Project Intake
The Data and Analytics team will accept project/enhancement requests through GitHub issues in the Sourcegraph analytics repository. At this time, requests that are not attached to a GitHub issue will not have an assigned analyst/engineer or expected completion date, and will not be tracked by the team.
Examples of requests that require an issue:
- New dashboard or enhancement to existing dashboard
- Ad-hoc analysis (e.g. “I would like to know the number of MAUs for the Batch Changes feature.”)
- Implementation of new business metrics (e.g. “Can we start tracking page views of our case studies?”)
- Bug fixes in data pipeline, transformations, or reporting (e.g. “I expect this value to be 100 and it shows as 50.”)
When creating GitHub issues, please include as much relevant information as possible. Please use the relevant issue template in the repository and fill out the requested information. If no template matches, create a blank issue and include as many details around your request as possible.
This information is useful:
- The problem: Describe the problem or question you have.
- End state: What is the end state of the project? What decisions will be made? Be as specific as possible (i.e. if the end state is a graph, draw out the graph in a tool or paper)
- The why: What will this request be used for? How does it support Sourcegraph’s company and team goals?
- Timeline: What’s the timeline of the project? Is it urgent? When does this need to be delivered, and how will it be followed up on in the future?
- People: Who is involved, and what are the expectations of each person? Who will be responsible for driving the project forward? Does each person have the necessary bandwidth for driving the project forward? Does each person have the necessary bandwidth to uphold the expectations asked of them?
- Frequency: Is this a one time ask or something that is needed ongoing? If ongoing, what is the cadence (daily, weekly, monthly, etc…)
A Data and Analytics team member will triage and assign issues to the relevant team member during sprint planning for items that are not time-sensitive or urgent.
For time-sensitive or urgent requests, please tag the issue with the urgent label. This will make the GitHub issue appear in the #analytics channel in Slack to ensure visibility, and where you can follow up with more details/asks.
Sprint Planning
We currently work in two week sprints that run from Monday to the following Friday. Requests that come in mid-sprint will be placed in the backlog and triaged at the next sprint planning meeting. If something is urgent, please let us know and we can prioritize as needed.
For larger data, reporting, or analysis requests, the first action will be to plan a scoping exercise for the analyst or engineer in order to size the level of effort and determine where it sits in the overall priorities.
General outline of our planning process:
- Thursday before a new sprint: synchronous sprint planning. Plan out the sprint 2-4 weeks out, and review the upcoming sprint
- First Monday of the sprint: send out a message to #analytics with the wins from the last sprint and the plan for the current sprint (and a link to 2-4 weeks out if anyone wants to look)
- First Friday of sprint: post updates to the issues in the sprint with a status and do an async review of where we’re at, if we need to push anything out or pull anything in
- Repeat
Planning Principles:
- OKR-driven
- Mix of quick wins and long-term, proactive projects
- Only choose projects where we have a clear picture of what the result looks like and the impact it will make; if these aren’t clear, we should block time to further scope them
Self-Service
Supporting a Self-Service framework for BI and Analytics is imperative to being a data driven organization.
This framework consists of three principles:
- Give the right people the right set of tools and capabilities
- Create a collaborative environment
- Create a process to govern how this collaboration leads to continuous improvement of our analytics capabilities
Personas
In our Self-Service framework, we need to accommodate multiple personas because not all users will want to self-serve the same way.
Viewers
- Viewers are interested in standardized reporting on standardized metrics. They are interested to see how metrics change over time and may want to drill into specific datasets for those metrics. Viewers will request new standard metrics or new filters on current standard reports. They will also request new views and reports. Viewers may want to create their own views or dashboards for their own personal use.
- Examples of use cases of a viewer _ I want to view standard/trusted reporting on multiple topics _ I want to filter results with a set of standard filters _ I have a set of metrics that I am measured against and want to track progress of those metrics _ I want to automate a set of metrics that I report out on regularly
Creators
- Creators are interested in all the components of a Viewer, but will also want to create their own views/reports. Creators will also want to perform ad-hoc analysis. They are interested in both standard metrics and new/undefined metrics. They may be able to write queries directly against a data warehouse. And creators will use our standard tools, but may use other tools that are not part of the Data and Analytics tech stack.
- Examples of use cases of a creator _ I want to create and share views/reports on multiple topics across multiple standard tools _ I want to perform ad hoc analysis _ I want to query the DWH to understand and analyze data quickly _ I want to automate analysis
Tools
Looker
Looker is a business intelligence tool used for standard enterprise reporting and ad hoc reporting and analysis. All Sourcegraph employees can have View access to Looker. Some groups have the ability to create reports. If you are not a part of a group that can save content, reach out to #Analytics in Slack.
Looker has the ability to connect to all data sources that are located in our BigQuery DWH. It can also connect to documents in Google.
Notable reports
Company level metrics If you’re looking for high-level data about how our user base interacts with our product generally, below are links to charts for some commonly requested data points. Unless otherwise noted, these charts include data for both free and paying users.
- Monthly users by instance type
- Instances by deployment type
- DAU/MAU
- Average seat consumption (MAU/Total Seats) - customers only
- Customer support tickets
- Growth dashboard (includes metrics like total searches per month, lines of code indexed per month, user retention etc)
- Technical health score
Customer-level metrics If you’re looking for product usage data for a specific customer(s), below are links to charts for some commonly requested data points. Please note that if you want to see a full overview of a specific instance’s usage, the dashboards in the “Full instance overview” section may be more useful.
- MAUs by customer
- Total user accounts by customer (monthly)
- DAU/MAU by customer
- Customers by Sourcegraph version
- Customer seat consumption (MAU/purchased seats)
- Deployment type by customer (ex. kubernetes, docker-compose)
- Hosting type by customer (ex. self-hosted, managed instance)
- Telemetry status by customer
- Code hosts by customer
- Total repos by customer
- NPS score by customer
- Customer support metrics by customer
Full instance overview If you’re looking for a full breakdown of usage on a server or for a particular customer, below are links to a few widely used dashboards that contain a variety of usage metrics.
- Customer account overview: A key dashboard we use to assess usage at a customer account (note: this is only for customers, free and prospect instances will not show up here). While more pared down than the following two dashboards, it contains the metrics we think are generally most important to measuring overall usage.
- Server instances dashboard: This dashboard is much more comprehensive than the customer account overview, but not every metric on here will be important/relevant for every user/customer. However, you can find free and prospect instances on this dashboard
- Technical health dashboard: This dashboard contains the account’s technical health score and the metrics that are included as a part of that score.
Feature specific dashboards and charts
Related useful links
- Metrics definitions
- Data sources of truth: Includes some definitions and links to data points owned/managed by Sales and Finance (ex. ARR)
Looker Enablement
Things to know about using Looker
- By clicking Explore from here or changing a filter on a dashboard, you will not change the underlying dashboard. Unless you explicitly click Edit, you are considered to be on your own temporary branch and will not change anything (even for yourself the next time you open the dashboard).
- When creating and editing dashboards, save individual tables and charts as looks instead of tiles directly to the dashboard. Looks can be added to multiple dashboards while tiles cannot be, and when look is edited, the changes will apply to dashboards where that look exists.
Looker Users
When adding a user to Looker, they need to be in both the group and role:
- Engineering, marketing, customer support, people ops, talent users = View
- CE, sales, product users = ‘All internal users, view and edit’
- Any other teams not listed should default to ‘View’
- Generally, CE, sales, product, customer support, engineering, and marketing receive accounts when joining the company
Amplitude
Amplitude is a business intelligence tool for product analytics. It surfaces data and insight into customer and user behavior and can help optimize for desired outcomes. Amplitude is for product managers. It’s a space where they can create reports, perform ad-hoc analysis, and understand the user journey.
Amplitude tracks Sourcegraph cloud usage.
**Notable reports: **
- Cloud growth metrics: high-level growth metrics such as traffic, activation, and retention for Sourcegraph cloud
- Organizations on cloud overview**: **high-level growth metrics for organizations participating in our beta program on cloud
Amplitude Enablement
BigQuery
BigQuery is our central data warehouse. It houses raw product and application data and transforms it into usable and reportable data for Amplitude, Looker, and more.
Current Data Sources
- Pings
- Sourcegraph.com
- Cloud events
- Marketing site events
- Zendesk
- Salesforce
- Hubspot
Success Metrics
OKR tracker (Here) - Our quarterly OKR tracker
The team will continue to build metrics to quantify the team’s success.